系统之家装机大师 V1.5.5.1336 官方版
系统之家装机大师是专为小白用户打造的装机工具,操作简单,适合32位和64位的电脑安装使用,支持备份或还原文件,也能通过系统之家装机大师,制作U盘启动盘,智能检测当前配置信息,选择最佳的安装方式,无广告,请大家放心使用。

时间:2021-09-20 16:30:40
发布者:admin
来源:当客下载站
SPSS怎么进行数据变量合并?比如在收集地区数据时,需要不同地区的人员分开收集,而在数据汇总的阶段,就需要使用到数据合并的功能将这些不同来源的数据合并汇总。下面小编就带着大家学习一下怎么进行变量数据的合并吧!
操作方法:
一、打开需合并的数据
变量合并的作用是将不同数据文件中,相同个案的不同变量数据进行合并。比如数据A包含了年龄、性别等数据,而数据B包含了地区、收入等数据,而这些数据都是来自同一批个案,就可以通过变量合并数据。
首先,在SPSS中分别打开两个需要合并的数据文件。
 图1:打开数据
图1:打开数据如图2所示,可以看到,两个数据文件中存在着账号、性别、客单价三个相同变量,以及Area、地区、来源、点击页面数四个不同变量,其中地区与Area实际为同一个变量,但命名方式不同。
 图2:对比变量差异
图2:对比变量差异二、使用变量合并功能
接着,如图3所示,依次打开数据-合并文件-添加变量,针对数据文件的异同点进行变量合并。
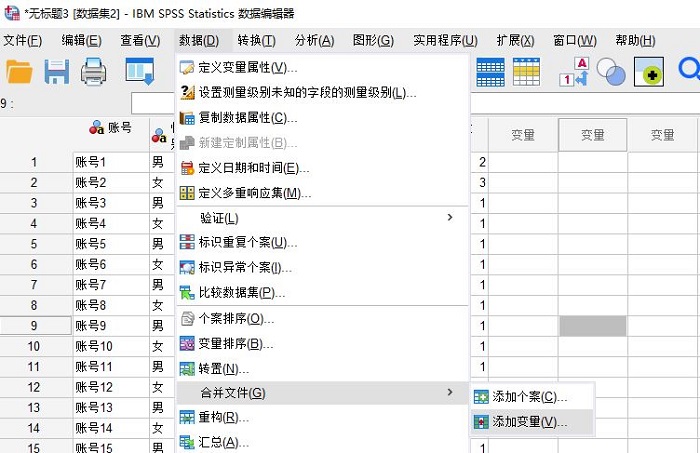 图3:变量合并功能
图3:变量合并功能由于当前打开的是数据集2,因此最终的数据会合并到数据集2中。如图4所示,以数据集2为基础,与之前已打开的数据集3进行合并。
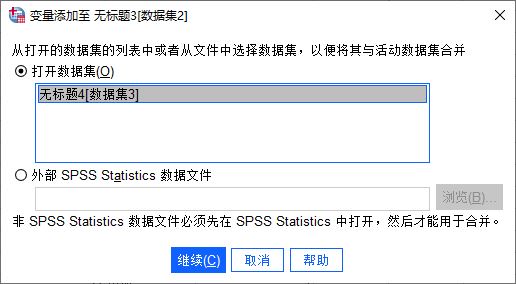 图4:指定合并的数据文件
图4:指定合并的数据文件接着,如图5所示,打开变量选项卡,进行变量合并的设置。
其中,变量括号中含+的是数据集2中不包含的变量,而含*的是数据集2中包含的变量。设置的变量含义如下:
排除的变量,即两个数据文件中存在差异的,但在合并数据过程中需要剔除的变量。
包含的变量,即两个数据文件中存在差异的,但在合并数据过程中需要保留的变量。
键变量,即两个数据文件同时包含的变量。
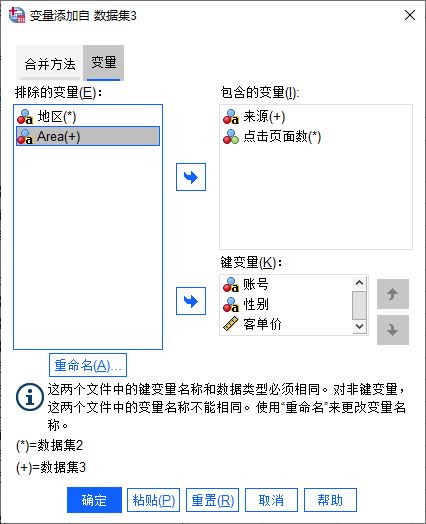 图5:设置变量的合并方式
图5:设置变量的合并方式由于变量“地区”与“Area”实际为同一变量,可将其中一个添加为“包含的变量”,另外,还可以通过重命名的方法,将“Area”重命名为“地区”。
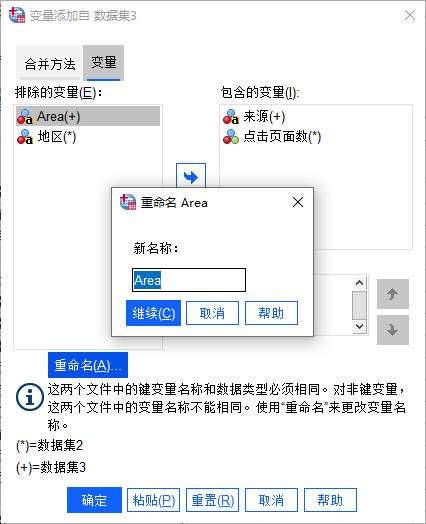 图6:重命名变量
图6:重命名变量如图6所示,可以看到“Area”已重命名为“地区”,将其添加为“包含的变量”。
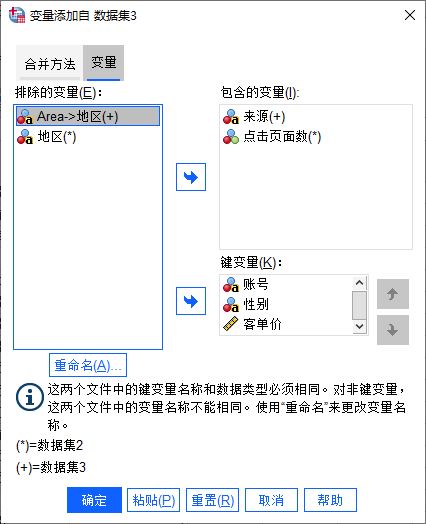 图7:完成变量的重命名
图7:完成变量的重命名如图7所示,在包含的变量中,“Area”变量已经重命名为“地区”变量。当然,我们也可以直接使用数据集2中包含的“地区”变量。
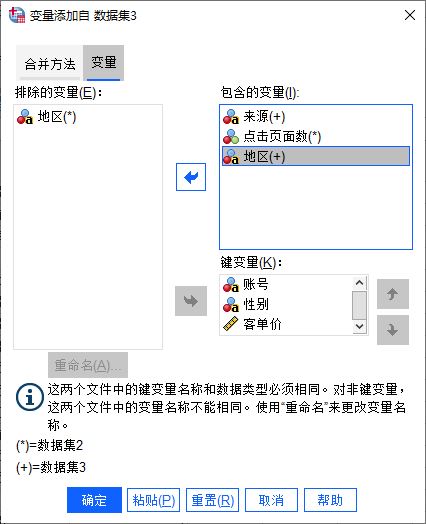 图8:添加重命名后的变量
图8:添加重命名后的变量完成以上操作后,如图8所示,可以看到,变量已经合并完成。后续,可对数据作进一步的整理,如排序等。
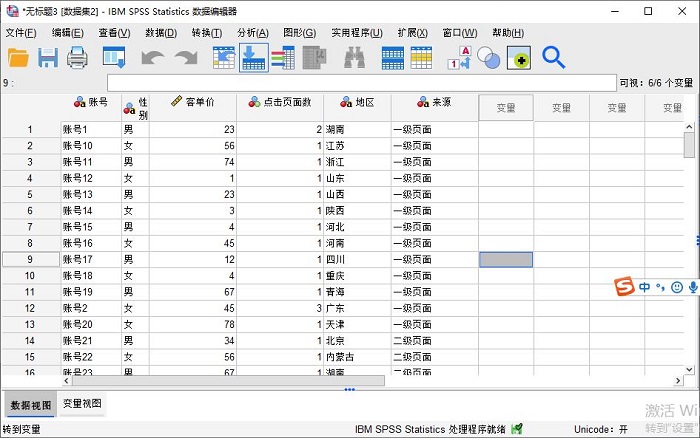 图9:完成变量的合并
图9:完成变量的合并以上就是SPSS数据合并中的变量合并操作演示。
热门教程 周 月
最新软件
系统之家装机大师 V1.5.5.1336 官方版
系统之家装机大师是专为小白用户打造的装机工具,操作简单,适合32位和64位的电脑安装使用,支持备份或还原文件,也能通过系统之家装机大师,制作U盘启动盘,智能检测当前配置信息,选择最佳的安装方式,无广告,请大家放心使用。
Win10 KB5022282补丁 官方版
Win10 22H2累积更新补丁KB5022282已经发布了,大家可以通过系统更新中心接收,或者直接当客下载更新补丁包,安装后的系统版本升级为19045 2486,此次更新包含针对最新安全威胁的保护措施,如有需要的用户,欢迎到本站下载。
Win11 KB5022364离线更新补丁 官方版
据当客小编最新消息,微软公司发布2023年第一个Bate补丁Win11 KB5022364,此次更新补丁不仅可以解决部分导致任务栏上半部分被截断的问题,还修复了某些情况开始菜单无法正确显示的情况,接下来本站为大家提供下载地址,欢迎有需要的小伙伴前来下载。
Win11 KB5021255离线更新补丁 官方版
Win11 KB5021255离线更新补丁是微软今早刚发布的最新补丁,用户可以升级补丁至内部版本22621 963,此次更新不仅为用户解决了可能影响任务管理器的问题,而且针对DPAPI解密进行了一定的改进,接下来本站为大家提供补丁下载。
石大师U盘制作工具 V1.6.1.175 官方版
石大师U盘制作工具是一款非常专业的系统装机软件,该软件支持一键系统重装、U盘重启、备份还原等,用户可以根据自身需求自行选择安装方式,支持所以品牌重装系统以及一键装机原版系统,操作简单,无需任何操作技术,有需要的用户快来下载吧。
石大师一键重装系统 V1.6.4.104 官方最新版
石大师一键重装系统是一款帮助用户实现一键重装的软件,同时还支持制作万能U盘启动盘的工具,提供win11、win10、win7、winxp等各种系统版本的一键重装,功能强大,兼容性强,就算是小白也可以快速装机,感兴趣的快来下载吧。




